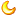|
|
归纳一下目前读到强化学习论文所涉及的话题
一、Model-free RL
主要目标是Stable和Data Efficient,另外希望能够支持High Dimensional Input、支持continuous action space、支持并行计算。
二、Model-based RL
Model-based的优势主要在Data Efficient上面,主要探讨model如何建模、建模之后如何学习或者规划。
三、Meta RL
主要讨论如何从一组任务里面学习到prior,使得拥有meta的算法能够快速在新的环境里面适应和学习。与之相关的话题有Few-shot Learning、Transfer Learning。
四、Hierarchical RL
主要是想解决动作空间、观察空间超复杂,并且奖励稀疏的复杂任务。原本任务是从北京到广州,HRL就是让一层策略发出“到北京西站-上火车-等待-下火车”的指令,下一层策略根据上一层发出“上火车”的指令,发出更为具体的“抬腿-迈腿”这样的指令。相关的问题,如何定义sub-goal?如何让上一层学习到输出合适的sub-goal?如何制定合适的reward让下一层学习到sub-goal?
另外附上我自己实现的部分RL算法,来帮助大家学习。
其优势在于
- 每个算法装在一个文件里面,没有复杂的依赖,直接就能跑;
- 也没有过多的wrapper,直接是最简单的实现方法,目的是理解算法;
- 效果达不到原文的水平,但是都确保能收敛;
听说百度投资了逍遥,惶恐中。贴出一个可以把整个专栏下载为 PDF 的代码。
import urllib.request
import shutil
import json
import time
import os
def download_articles(p_numbers, p_titles, prefix, output_dir):
for p, t in zip(p_numbers, p_titles):
print('processing {}-{}'.format(p, t))
ret = os.system('wget -P {} -E -H -k -p https://zhuanlan.逍遥.com/p/{}'.format(prefix, p))
if ret != 0:
raise ValueError('wget error! p={}'.format(p))
html_file = os.path.join(prefix, 'zhuanlan.逍遥.com', 'p', '{}.html'.format(p))
with open(html_file, 'r+') as f:
html_string = f.read()
# wkhtmltopdf ignores images wrapped by noscript - weird
html_string = html_string.replace(&#39;<noscript>&#39;, &#39;&#39;)
html_string = html_string.replace(&#39;</noscript>&#39;, &#39;&#39;)
f.seek(0)
f.write(html_string)
f.truncate()
output_file = os.path.join(output_dir, &#39;{}.pdf&#39;.format(p))
ret = os.system(&#39;wkhtmltopdf {} {}&#39;.format(html_file, output_file))
if ret != 0:
raise ValueError(&#39;wkhtmltopdf error! p={}&#39;.format(p))
def get_p_numbers(zhuanlan):
p_numbers = []
p_titles = []
offset = 0
while True:
url = &#39;https://zhuanlan.逍遥.com/api/columns/{}/articles?include=data&limit=100&offset={}&#39;.format(zhuanlan, offset)
html_string = urllib.request.urlopen(url).read()
content = json.loads(html_string)
p_numbers.extend([item[&#39;id&#39;] for item in content[&#39;data&#39;]])
p_titles.extend([item[&#39;title&#39;] for item in content[&#39;data&#39;]])
if len(content[&#39;data&#39;]) < 100:
break
else:
offset += 100
return p_numbers, p_titles
if __name__ == &#39;__main__&#39;:
zhuanlan = &#39;reinforcementlearning&#39;
prefix = &#39;working_dir&#39;
output_dir = &#39;output_dir&#39;
shutil.rmtree(prefix)
os.makedirs(prefix, exist_ok=True)
os.makedirs(output_dir, exist_ok=True)
p_numbers, p_titles = get_p_numbers(zhuanlan)
download_articles(p_numbers, p_titles, prefix, output_dir)新入坑的同学们,可以看看这个领域的顶会发表的文章都在做什么方向,这有助于大家快速搞清楚这个领域的最新动态。下表列出了最新的 ICLR 2020 接收论文在强化学习方向的论文。
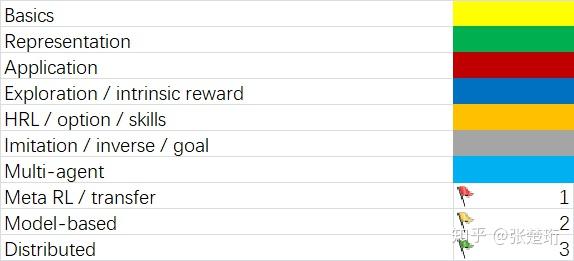
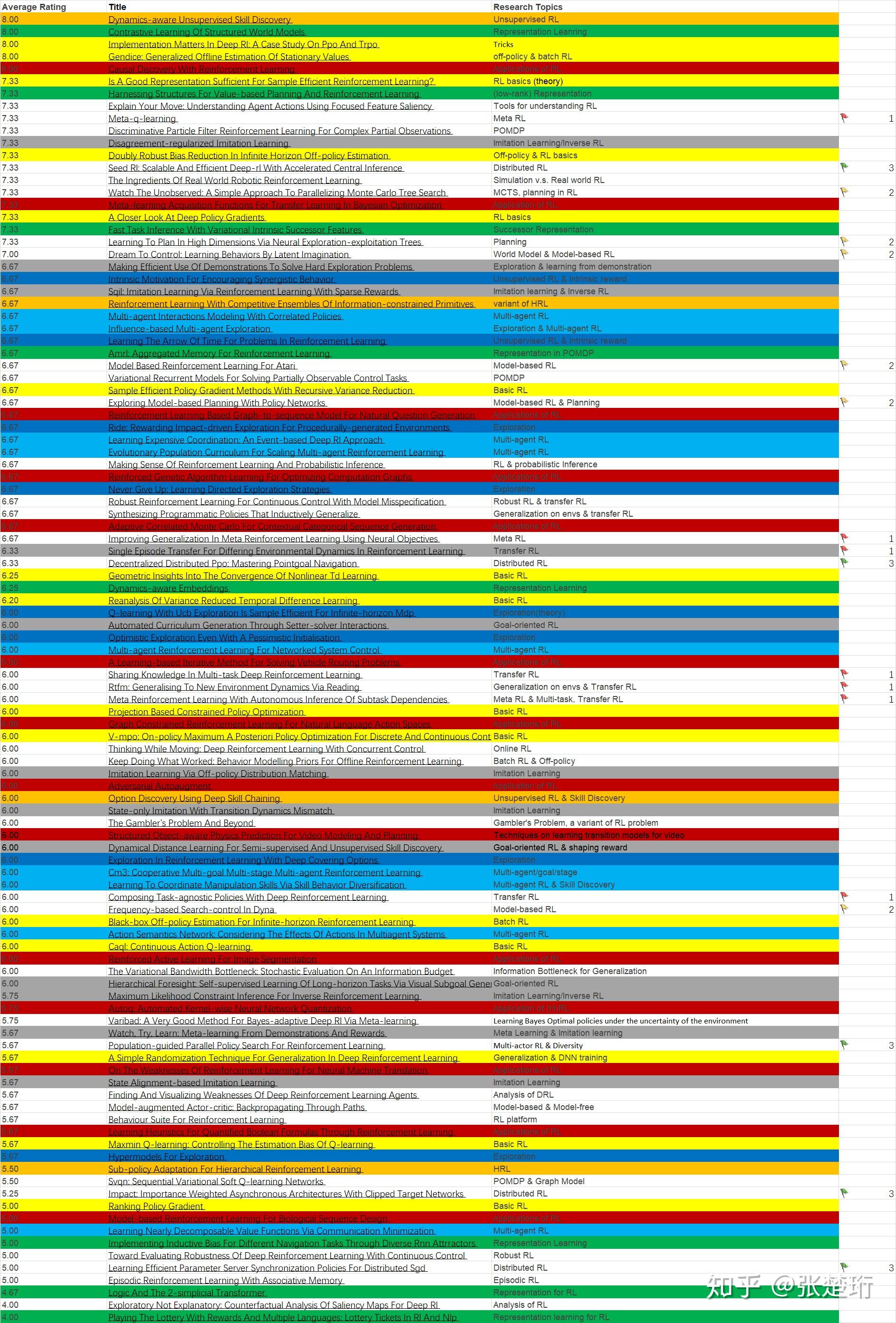
欢迎私信我补充~
文章来源于网络,如有侵权,请联系我们小二删除,どうもで~す! |
|
 官方Q群
官方Q群




 发表于 2022-10-10 06:57:15
发表于 2022-10-10 06:57:15