设为首页
收藏本站
收藏
任务
排行
道具
勋章
官方Q群
群名:XY
群号:39764938
简介: 19
点击快速入群
魔方挑战
消消乐
合成大西瓜
召唤神龙
挑战五子棋
吃货鉴定
头条
知日
热点
理财
美女
旅游
视频
美食
搜索
搜索
热搜:
活动
Hi~
登录
或
注册
本版
帖子
用户
逍遥网
»
日本
›
FUN TIME
›
美女
›
【全网最细节】AI绘画的原理到底是啥
返回列表
发新帖
查看:
767
|
回复:
0
【全网最细节】AI绘画的原理到底是啥
[复制链接]
庞先生
庞先生
当前离线
积分
26564
1万
主题
1万
帖子
2万
积分
商家A
积分
26564
发消息
发表于 2023-4-6 15:05:51
|
显示全部楼层
|
阅读模式
来自: 中国广东茂名
关键概念
ai绘画:
主要功能为包括:用文字生成图片(专业术语为:文生图,现在最火的就是文生图);图像修补(智能调整图片中选定的区域,或者智能补充图片外的信息);风景合成(简笔画变图像)
噪点
:
在本文中,特指图片中的白色像素点,可以理解为往正常的图片中添加白色像素点,就像日常生活中的噪音一样。
扩散模型Diffusion Model
:
所谓扩散算法,是指先将一幅画面逐步加入噪点,一直到整个画面都变成白噪声。记录这个过程,然后逆转过来给AI学习。AI那里看到的是一个全是噪点的画面是如何一点点变清晰直到变成一幅画的,AI通过学习这个逐步去噪点的过程来学会作画。这个算法出来之后效果非常好,比以前的AI绘画效果要好的多。突破了实用化的临界点。
开源:
指公开软件的源代码,允许他人学习使用,就像把自己的作业本给别人免费抄。这波ai绘画的爆发源于Stable Diffusion的开源。
Stable Diffusion(ai绘画模型,直译为稳定扩散,但业内人都称呼英文名字):
Stability.ai公司于2022年8月份发布并开源的AI绘画模型,需要翻墙,需要付费(试用次数很少),可以高质量生成ai作品,是这波ai绘画爆发的起始点。当然,这一波爆发仅在ai绘画圈内,对行业外的人影响不大。
Novel AI(ai绘画模型,无中文名字)
而到了2022年10月份,基于Stable Diffusion的二次元AI绘画模型NovelAI横空出世,NovelAI强大的二次元插画绘图能力,使其一跃成为全球最好的动漫插画生成模型。正是novel ai使ai绘画的事情彻底出圈,因为二次元的受众非常广。
Prompt(直译为关键词,中文英文都可以称呼)
即生成ai图片的指令,除了关键词,我们还需要设定:步数Step、种子Seed
ai绘画的前世今生
AI绘画其实在很早以前就出现了,只不过那时候的效果不尽人意。
而在最近几年出现了一个名为‘’概率去噪扩散算法(Diffusion Model)‘’,在这种算法的加持下,各种AI绘画模型才开始开始层出不穷,但是这些早期的AI绘画模型要么被大公司长久把持(例如OpenAI公司,他们早在2021年就推出了Dall-E 1AI绘画模型,并未开源),要么生成图画的效果不佳,还达不到破圈能力。
直到Stability.ai公司于2022年8月份发布并开源了Stable Diffusion AI 绘画模型,这才彻底让AI绘画热潮爆发!
Stable-Diffusion 免费、生成速度又快,每一次生成的效果图就像是开盲盒一样,需要不断尝试打磨,所以大家都疯狂似的开始玩耍,甚至连特斯拉的前人工智能和自动驾驶视觉总监 Andrej Karpathy 都沉迷于此
Stable Diffusion采用的底层算法与普通的扩散算法不同,它在其外面还套了一个VAE模型,因此达到了更快的画图速度和更高的画图质量
而到了2022年10月份,基于Stable Diffusion的二次元AI绘画模型NovelAI横空出世,NovelAI强大的二次元插画绘图能力,使其一跃成为全球最好的动漫插画生成模型
总的来说,目前比较前沿的AI绘画模型有:Stable Diffusion,Disco Diffusion,Midjourney,DALL-E 2,NovelAI。
前两者的模型是开源的,而后三者未开源。
国内的AI绘画小程序也是在最近8,9月份开始兴起的,他们使用的模型就是主要就是已开源的Stable Diffusion和Disco Diffusion,大家可能也尝试过,但效果并不怎么好而且还收费,效果不好是很正常的,因为普通用户输入的
prompt
没有经过专业训练,不规范,这个
prompt
后文会详细说明
不过就在最近,发生了一件有趣的事,未开源的二次元AI绘画模型NovelAI就在发布的那一天被一个黑客窃取,这个泄露的AI模型也就被公开在互联网上了,这也是为什么Novel ai没有开源,却流传十分广泛。
ai的原理
ai是什么
首先,我想我需要介绍一下AI是个啥?简单来说,人工智能 (AI) 是指可模仿人类智能来执行任务,并基于收集的信息对自身进行迭代式改进的系统和机器。AI 具有多种形式。例如:
聊天机器人使用 AI 更快速高效地理解客户问题并提供更有效的回答
智能助手使用 AI 来解析大型自由文本数据集中的关键信息,从而改善调度
推荐引擎可以根据用户的观看习惯自动推荐电视节目(摘自什么是人工智能 (AI)?| Oracle 中国)
QQ小冰就是个很好的例子,还有语音转文字,也包括你经常点进美女的视频然后视频平台疯狂给你推美女的技术,这些都写在大忙人AI的“工作合同”上。
不过这样一说好像还是不能太理解AI是啥?没关系,请看下面的一个例子:
假设有这样一个电脑程序rin,它的目标是猜出你心中想的一个数,现在你默念3,因为没有任何已知条件,所有rin随机地猜了一个数,5。 这个时候你微微一笑,轻语道:“猜大了”。 rin面露尴尬,眼神飘忽,沉默了好久才憋出一个字,“4?” 你觉得面前这个电脑程序似乎还挺有意思,便又对它展开了攻势。 “还是大了哟~还有两次机会呢。” rin似乎紧张起来了,嘴皮在微微颤抖。 “上两次都只减小了1,这次干脆减小2吧,对,一定是这样。” 于是rin给出了它的第三次答案——2。 你噗呲一声笑了出来,rin的脑子却开始有点宕机了,你盯着电脑程序的眼睛:“猜小了。” 虽然rin此时已经知道答案,但声音是如此的不自信,“......3?” 你拍桌大笑,感叹到这个电脑程序有多有意思。 ......
这样的一个能根据自己给出的答案被肯定与否调整策略的电脑程序就是一个很基础的AI,刚开始它根据输入给出的输出可能是完全随机的,但是当你说出这个输出结果是正确的还是错误的那一刻起,AI就在朝着正确答案一步一步前进,最终你肯定了AI的答案,AI在此处的工作也就结束了。
这样读者应该是对AI有个初步了解了。但是这跟画画有什么联系呢,我的评论是别急,再等我聊聊“AI普遍是预测器”这样的一个理论。
但是啥是预测器啊?预测器简单来说就是以收集到的客观事实为根据,对你的输入给出一个成功率最大的结果......好像有点难懂,同样,看下面一个例子(算是对一个浅显道理的阐述):
你每天回家都有一段路需要步行,但是一共有三条路程差不多的路。 第一天你走了左边的那条路,但是因为路面湿滑摔了一跤,你心想可能是今天倒霉。 因为你有选择困难症,第二天你又走了左边那条路,然后又摔了一跤,你咬牙切齿,骂了两句。 第三天你不信邪,觉得不能连着三天摔跤吧,还是选了左边那条路,但是果不其然,摔了个狗吃屎,你如此发誓:“我再走这条路我就是沙比。” 因此你第四天换了中间这条路,没有摔跤。 第五天你同样走了中间这条路,但是摔了,你心想虽然摔了跤,但是前一天没摔,明天再试试。 但是第六天你又摔了个狗吃屎,因此你换了右边的那条路。 结果你再也没摔过跤。 当你给同样要走这段路的人提起这件事的时候,我想这个人会很顺其自然地直接选择右边那条路走。
那么在这个例子中,你扮演的就是客观事实,下一个要走这段路的人就是AI,AI分析了走左边那条路不摔跤的概率是0,走中间那条路是1/3,而走右边那条路是100%也就是1。当你问AI“我走哪条路才能不摔跤呢?”AI理所应当会回答右边。
这就是预测器。根据:
(1)对你的输入——“我走哪条路才能不摔跤呢?”,
(2)客观事实——一个人走某一条路摔跤的概率,
(3)做出最有可能被你接受的结果——告诉你走右边,然后你走了100次就摔了一次,还是因为有人推你。
预测器能干啥呢?
在基本上所有能总结出一定规律的任务中,它能根据输入给出一个大部分人能接受的结果,具体的表现就是下围棋,因为围棋有具体的规则,而且甚至有定式,别人用A战术你用B战术最有可能胜利,AI学习了上万场棋局,在你下第一步棋的时候它就有一堆应对方式了,这个时候它可能会随机地选一种下法,然后根据你下的每一步棋调整战术;再比如你某一天点开了一个美女,第二天你会发现你的首页充满了美女视频,但同时也会有美妆视频,以及穿搭的视频,甚至还有R18的东西,这是因为AI分析了上万人,他们在看美女视频的同时也会看美妆和穿搭,以及R18,所以AI就自动认为你也是其中一员——这就是视频网站推荐的原理,分析看这个视频的人还喜欢什么,用上面的AI思维方式就是根据:
(1)对于你的输入——你点开的某个视频,
(2)客观事实——大部分点开这个视频的人还会看什么,
(3)做出最有可能被你接受的结果——推荐一些相关的内容,然后你刷了一晚上视频第二天早八迟到了。
总的来说,AI是一类总结规律的计算机程序,它需要大量客观事实(几百都有点少,几十甚至个位数根本学不明白)来总结规律,根据你的特定输入给出最有可能被你接受的结果,它的工作范围是任意能够总结出一定规律的任务,规律越明显越死它表现得越好(这就是AI为什么能拿围棋冠军但是画手脚很难看),而且它针对的目标是大部分人(AI作画为什么是流水线画风留着后面阐述),如果你很有个性那么AI更可能难以满足你的要求。
那么到这里我想读者应该对AI有了个初步了理解了,接下来我们深入一点。
1.AI将止步于何处?
AI理论上最终能代替任何职业的人,只是因为难度不同才有先后而已。
人类所有行为获取都是在这种行为是有规律可寻的基础上进行的(读者可以自己试着举出反例,我是举不出来),而AI本质是什么,是规律总结计算机程序。你知道开发学习了上万棋谱最终战胜人类棋手AI的团队之后干了什么吗,开发了个没学任何棋谱就能轻松干碎初代的AI。所以AI理论上是完成人类能完成的所有事情的,包括拥有感情之类的所谓人类特有的东西。
ai是怎么学习的
其实这儿一点在预测器的部分已经具体阐述过了,AI学习的流程就是根据带有结果和输入的客观事实,分析出每种输入最有可能对应哪种结果并输出,从而写出一本行动纲要以供日后参考,这个过程一般是由程序员完成,所以用户并没有参与到这一过程中。其中“根据带有结果和输入的客观事实,分析出每种输入最有可能对应哪种结果并输出,并写出一本行动纲要”,就是AI的学习过程,而当AI学习完毕,也就是写完了一本针对各种情况的行动纲要时,它就可以被部署了——用白话来说就是供用户进行使用了,输点关键词让AI给你画画。
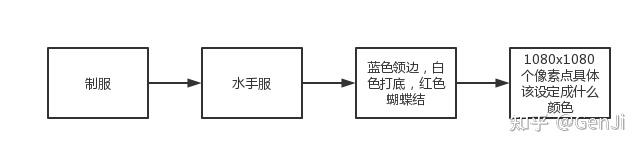
那么它是怎么学习别人的画呢?首先一位程序员拿到了一张作品,他用眼睛看出这张图上面是一个穿着裙子的女孩站在草地上,之后他用girl,standing on grass,dress标记了这张作品——对于其他作品也做如上处理,之后他便得到了一个包括了上万张图片的数据包,然后把这个数据包喂给了AI。AI思维如下,根据:
(1)你的输入——(日本校园制服)japanese school uniform
(2)客观事实——大部分被打了uniform标签的作品都画了制服,制服的特点是可能有蝴蝶结,下装一般穿短裙,一般是水手服等等
(3)做出最有可能被你接受的结果——画了一张穿水手服,提着单肩包,穿着小皮鞋和长筒袜的美少女。
我们也可以再进一步跟随AI深挖它是怎么知道水手服的样式。根据:
(1)上一层输入——水手服
(2)客观事实——大部分水手服都是蓝色白色
(3)做出最有可能被你接受的结果——画了蓝色领边白色打底红色蝴蝶结的水手服
我们再一步深挖AI是怎么学习水手服具体是怎么画的,比如轮廓是怎样,袖口长啥样,根据
(1)上一层输入——蓝色领边白色打底红色蝴蝶结的水手服
(2)客观事实——大部分蓝色领边白色打底红色蝴蝶结的水手服在整张图里的A位置的像素点颜色为RGB表示的(12,70,9)(数字乱填的,这是啥颜色我也不知道),B位置有个像素点,以此类推。(在此补充一下计算机图像学的知识,计算机是如何显示一张图片的呢,那就是设定每一个像素点的RBG值,就像是那些老旧的广告灯牌,设定每个灯泡的颜色来组成“洗剪吹”的字样)
(3)做出最有可能被你接受的结果——即你得到的结果
在经过多次深挖后,AI觉得它的行动纲要写得差不多了,它的学习也就停止了,这个时候它得到的是一本如上一步步深入到底层的行动纲要,当接受你的输入后,它会一步步查到底,直到行到纲要告诉它这个像素点该画什么颜色。行动纲要看起来可能会像这样
没错,最基础的AI在一幅1080x1080的图片上要对这1080x1080个像素每个进行一次处理,也就是一共1080x1080次处理!这就是为什么要跑AI的电脑性能不能太差,而且你的电脑在跑AI的时候风扇会像个直升机一样呼呼转!
为啥AI要像这样学习?人工智能其实可以归于仿生学,它的学习方式是在研究了人类学习方式后,用计算机的方式来进行表达的,具体的就不展开讨论了,涉及到专业知识,只需要知道AI的学习方式是简化的人类学习方式就行了!我们共用的是一套类似的学习方式!数据库里的作品也是学习完后就不会再用的了,也就是说之后AI画画是彻底与作品无关了!不然你想跑个AI还得下载那上万张图片?那也太离谱了!
ai是怎么知道要画什么的
这个其实部分涉及到自然语言处理,这是AI研究另一大领域,此处不展开讨论,我们只拿novel ai讨论如girl,black hair,smile,uniform这样的输入。
先简单介绍一下novelai:novelai可以将文字描述的场景或者是上传图片的图片内容,经过AI合成后形成新的绘画内容展示出来,你的输入是形如school uniform,girl,black hair,smile,uniform这样你想要的元素和glasses girl,missing fingers,missing legs这样你不想要的元素或者bug,输出是一张与关键词有关的图片。
现在我们来理解AI是怎么知道画什么的:
首先假如你的输入是school uniform,girl,black hair,smile,uniform(你不想要的关键词此处不讨论,在后面会详解),那么AI首先会把这几个词拆开并记住,然后到它的行动纲要中查找对应解决方法,也就是学习得到的
但是如果你给的词有冲突,比如水手服,渔网袜,但是你又给了高中生,小皮鞋这样的关键词,那么AI此时的内心如下:
“哎我去这人有问题吧,水手服是清纯的象征,渔网袜走的性感,这俩能放一起?”
如果遇见懂变通的AI:
“哦你后面还加了更多跟水手服有关的关键词啊,那我就当你渔网袜打错了吧。”
于是你得到的是穿着黑丝和水手服的女高中生
如果遇见固执的AI:
“唉你开心就好,画出来怪也别怪我,谁叫我行动纲领里面没写呢。”
于是你真的得到了穿着渔网袜和水手服的女高中生,但是上身水手服,下身渔网袜黑高跟鞋。(哎,那这不就是缝合吗?别急,后面会讲区别)
如果遇见中庸的AI:
“你这又要清纯又要性感好难办啊,但是结合起来又很怪,看你水手服的关键词较多就给你画3张水手服女高中生,2张性感御姐吧”
于是你得到了3张没有渔网袜和性感元素的水手服女高中生和2张性感的制服御姐。
AI决定到底要画什么的时候,就像是人在看着菜单选披萨一样,你可以选烤肠披萨也可以选夏威夷披萨,或者是来个双拼,只不过AI选披萨具有一定的随机性,不像人一样能想想昨天吃了啥,只是例如某款披萨有优惠可能会影响AI的选择——AI局限于菜单上有啥。
这是对于由词条生成图画的AI,既用词条又用参考图的AI同理,只是在已知条件加上AI从图中看出的东西,如果图过于模糊,AI可能就只会取颜色当已知条件了。
哎但是,不是听说放在前面的词优先级较高,AI咋取舍的?哦~这个就像是你去玩抽奖游戏,商家告诉你一种玩法100%中奖但是最高奖品是1块钱,但是另一种玩法只有30%的概率中奖但是最高奖品是一百万,你肯定会选第二种玩法吧。
好了,现在我们的AI决定好画什么了,但是要怎么下笔呢?其实方法跟决定画什么基本一致,只是把输入从你给的词变成了它决定要画的东西,也就是水手服,然后查查行动纲领,一直深入直到纲领上写着把某某像素点画成白色,而我们的ai也像这样做了。处理完所有的像素点,ai得意地放下了画笔,我们得到了一幅画。
AI是怎么从一幅模糊的图越画越好直到画出一张artbook级别的作品的?
再进入这一节之前,我希望读者可以花一点时间看完以下这个视频来直观地了解AI是怎么作图的:
https://b23.tv/nvZXTtN
前几次STEP生成的图片
如果你已经观看了此视频你或许会很疑惑,“我去,它是怎么从一幅模糊图画变成成稿的?”
以下为扩散模型Diffusion Model的讲解,大部分ai绘画原理都是这个。
直观来说,AI 为了学会作画,它会先去尝试理解,为什么某段文字会和某张图片是相似的。在看了足够多的例子之后,它就隐隐约约能捕捉到文字和图片的联系了,此时只要给它一段新的文字,它就会根据它的理解,去一点一点地把相似的图片给“画”出来。这里所谓的“一点一点”,正是它“一步一步”的去噪(去除噪音,即白色像素点)过程:
1. 一开始,它会知道最终的图片需要和什么文字相似,然后会面临一张全是噪声的“图片”
2. 此后的每一步,它都会把当前“图片”中的噪声给去掉一点点,以使去掉噪声后的“图片”尽可能与所给的文字相似
3. 等漫长的去噪过程结束后,就能得到一张符合文字描述的图片了
当然有个比较流行的梗就是,因为你给 AI 资料,它真的会去学怎么画,而且是没日没夜地去学!!!
这就是绘图AI,我想现在读者应该理解了为什么AI能从一幅模糊不清的图迭代出一张成稿。
为什么AI会画出邪神?(negative prompt的意义)
AI作图时有可能会出现缺胳膊少腿的情况,甚至一只手有6根手指,这不经让我们怀疑这不会是个人工智障吧。
但是出现这种情况是有原因的,如下阐述:
当你要求AI画出水手服女高中生的时候,你没有给定具体的姿势,所以在AI的眼中,画站着坐着成功的概率是一样的,假设都是50%,那么AI一想,我画一个又是站着又是坐着的,那成功的概率不就是100%?你也没说不行对吧,嘿我可真聪明。于是我们得到了一幅四条腿美少女的画。所以现在我想读者对negative prompt的意义应该是理解了,negative prompt(负面关键词)的作用就是告诉AI我不想要多出的手脚,我也不想正常手脚没了。
错误地生成了肢体
AI作画到底是不是缝合?
不是,对于AI来说缝合比自己画难多了。
我觉得上面那个链接的视频里展示了挺多区别了,而且认真看完上面内容的读者应该也能看出AI作画跟缝合还是有挺大区别的,这一节主要思考一下如何写出一个缝合的算法(白话,放心)。
与从0开始画一幅作品不同的是,缝合AI要学习的是各个部分的相关性,如何把一部分完整地剪切下来,同时处理拼接处使其平滑。
那么我们现在从程序员处理图像开始:
某程序员现在拿到了一些作品,他要给这些作品打上标签,现在是第一张图——穿着短裤短袜和运动鞋的运动系少女,他打上了第一个标签运动系少女,但是第二个标签难住他了,他打上了短袜的标签,但是现在面临的问题是这整张图只有部分是短袜,而缝合AI的要求之一就是把相关部分完整地剪切下来,于是他只把图中短袜的部分给标记了,但是画长裤的时候怎么办,短裤可以让短袜的上面部分露出来可长裤会遮住一部分,那么我们就还要要求AI会裁剪......
是不是发现缝合AI反而变复杂了,而事实的确是这样,所以我开发一个会缝合的AI可能还不如开发一个会画画的AI。
以下内容中的观点来自网络
AI有没有创造力?(其中简单地说明了AI的运行原理)
首先明确,AI是可以有创造力的。
我们思考一下,现在市面上的绘图AI是为了解决什么问题而开发出的?是为了快速且低价地提供大量满足甲方需求的图片,或者是为画师提供灵感。明确这一点之后我们再回过头来想想,为了满足这样的需求AI需要有创造力吗?答案是否定的。我不认为会有一家动画公司或者游戏公司给画师提的要求会是“提供一幅具有艺术美感的图片”,而更像给AI绘图提供的关键词——白色头发,红色眼睛,穿着夹克,运动系......
那么AI能有创造力吗?AI能有自己独特而的画风吗?这是如何实现的?
前两个问题的答案是肯定的,至于如何实现,我们可以类比AI学习画画的过程:
(1)刚开始AI画的东西都是随机的,它并不知道要画什么,但是你会告诉它画的好还是差
(2)经过大量试错,AI偶然生成了一张你觉得看起来还算有线条轮廓的图,但是画的什么你也看不出来,但是你告诉AI这张稍微好点
(3)AI分析这张“稍微好点”的图片,总结特点,按照总结的特点继续试错
(4)重复1-3
这样经过大量试错,AI画出了一张看得出来是人的图片,再经过大量试错,AI画出了一张有独特画风的原画级别的作品,并且形成了自己特有的画画方式和画风。
在这个过程中,我们甚至能加入随机的干扰,比如让这个AI是色盲,让那个AI不能使用红色,这样我们就得到了不同画风的AI,而且是从0开始,没有学习任何人。
总结一下,目前所有的绘图AI都不是为了创造艺术作品而被开发出的,他们的开发目的是快速提供大量满足具体要求的产品,创造艺术的AI不是不能被开发出来,只是现阶段没有商业必要
一些问题
我看现在各大社交平台上面支持AI作画的和抵制的真的吵得不可开交啊,笔者认为这是信息不对等造成的,人工智能工程师觉得被说他们的AI是电子裁缝是一种侮辱,画手觉得这是一种威胁也是一种侵权行为,资本家只想着怎么降低成本,普通人可能就只想着我把野兽先辈丢进去会出来什么......
笔者只在这里丢出问题以及个人分析,不过答案我认为就算我分析了也会有反对的,但是这一部分其实是激起多方思考,之后才能达成共识
(可能会让人血压升高,但是本意是要解决问题啊,毕竟我们人工智能领域的工作者更希望的是自己开发的东西被更多人承认和使用啊)
是否需要对AI快速抢占市场而担心失业?
援引b站某视频评论区的一段话:“短期来看,能让好的画师地位更高,差的画师没饭吃,这样对于大部分人来说可以更廉价的获得不那么好的画,甚至有望去降低动画成本。是好事
但是长远来看,一个好的画师的画技也是一点一点进步的,必然会经历技术差的这一阶段,也就是会很久都吃不上饭。而这会导致新人不敢入行,进而导致无法产生新的顶级画师。是坏事,是急切需要解决的问题”
AI作画给哪些人提供了便利?
一些需要流水线作品的公司,如动画公司和游戏公司,一些没有能力画画但是想参与到一些二次元活动的人,想要人物设定图和插图但是没有经济能力约稿的作者,大部分画师(毕竟线稿变上色了的成稿,打几个关键词就能帮着设计场景动作的工具还是挺好用的),等等。
AI作画的双刃剑?
万恶的资本家一直在寻找快速且低成本的解决方案,而AI作画的确在一定程度上让他们得逞了。AI作画的确是会淘汰掉一部分中底层画手,特别是没什么自己画风的画手,同时缩小整个行业的体量,增大失业率,同时由于一些人丢掉了工作加入了其他行业,其他行业竞争也会更加激烈。
但是同时AI作画提高了作画的效率,也就是说游戏的开发会更快,动画的制作也会变快,画师在相同时间内能完成的稿子数量也会增加(当然一张作品的价格也可能会往下降,所以是好是坏难以讨论),而且能让底层和中层的作者以及其他需要流水线作品的人和有自己独特画风的画师收益(AI学习需要大量样本所以有自己个性的大大和太太根本不用担心...除非你是肝帝画同一个姿势的人画了几百张)所以短期来看我们只能持观望态度,没必要盲目抵制和盲目吹捧。
AI作画涉及侵权吗?
这个问题我不讨论,版权保护一直是一个问题,而且没有是非正确与否(比如笔者曾经见过的一个问题:“如果一个国人盗版开发出了英特尔芯片,他会被嘉奖还是蹲大牢?”),所以笔者的态度是,版权保护固然重要,但是并没有必要过分钻牛角尖,有时更关注自己的用户体验可能会更开心。
普通人使用AI作画应该被批评吗?
首先我们应该达成一个共识——资本家才是应该被批评的对象。
程序员开发出这个AI本意绝对不会是消灭中底层画师,我们更希望的是让这个世界发展的脚步更快,为人们包括自己带来更好的生活质量,程序员我想应该不是被批评的对象。
普通人使用AI作画我想更多的是为自己带来乐子吧,把室友的脸丢到参考图那里看看会是怎么样,或者是参加一些原本只有会画画或者有财力的人才能参加的活动,也应该不是被批评的对象。
对于个别愿意使用AI作画的画师,他们只是更快接受了这一项技术而已,毕竟AI作画会对绘画行业带来怎样的影响不是这几个月这几年就能看得出来的,我想他们也不应该成为被批评的对象。
要我说谁最应该被攻击的话,那一定是资本家。现在年轻人为啥会躺平,还不是我创造的一切价值最终都成为了资本家的玛莎拉蒂上的一颗螺丝呗。年轻人躺平,资本不满足,不够他们收割,于是变本加厉,当赚够钱之后就溜了,享受漂亮国的“香甜空气”。在整个AI作画风波中,程序员和画师都是受伤的对象。程序员不开发出点东西没有饭吃,画师没有稿子画也没有饭吃,于是资本想到一个绝妙的主意,把多方矛盾点燃,自己拍了拍屁股数钱去了,转移矛盾这招对于资本来说是惯招了。
技术不应该被批评,这是时代的进步,开发算法的人不应该被批评,他们是推动时代进步的工匠,普通人也不该被批评,世间从来就不是非黑即白,擦亮双眼,团结力量,我们要把铁拳砸到资本头上!
最后放上我的一个画师朋友给我看的一张图,经此事可谓士别三日刮目相看,她应该是属于绘圈最先能接受AI作画的一批人吧(也许抢占了先机?)
伦理问题
目前AI绘画的作品没有明确的版权,这方面也没有相关法律,所以图像的创作者可以任意复制、修改、分发自己创作的作品,甚至用于商业目的,不需要征求任何许可。
但是你在输入的的提示词中,涉及到风格特别鲜明的艺术家或者商业作品,那么渲染生成的图像会呈现出非常相似的风格,这样自然就会涉及到侵权的问题了。如果你想将图片用于商业目的,还是要谨慎,注意规避这些潜在的风险。
现在很多人都对AI入侵人类艺术领域而感到担忧,这种担忧是完全没有必要的,一方面是因为他们缺乏基础的人工智能学术领域的知识,另一方面是他们被立场取代了思考。AI的概念早在上世纪50年代就被提出来了,但受制于当时的计算速度没有得到较大的发展,直到近十年出现的各种强大的计算机芯片/显卡的辅助下,AI才得以蓬勃发展,但它最终都会受限于硬件,而硬件取决于基本物理学,不知道你有没有发现,当前你我的生活之所以感到日新月异,仅仅只是信息互联网产业在迅速发展,实际上能源,动力,材料,半导体等领域,以及最重要的基础物理学的发展已经缓慢到接近停滞,百年前创造的量子力学,相对论当今依旧可以被定义为尖端物理学,今年的诺贝尔物理学奖也只是证明了量子纠缠确实存在。
话说回来,经过我这几天本地测试的体验来说,AI绘画仅仅只是新时代产生的绘画工具,它的缺陷非常明显,AI绘画绝对取代不了人类画师,但凭借它快速的出图速率,精美的效果,它完全可以淘汰一些中底层的人类画师。
Ken哥(Nolibox CTO)的讲解
LDM相关
目前这一波 AI 绘画的浪潮,是由 Stable Diffusion 带来的。Stable Diffusion 背后的技术是 Latent Diffusion Model(LDM),而 Latent Diffusion Model 是 Diffusion Model 的一种变体。为此,我们会从 Diffusion 模型讲起,逐渐地往 Stable Diffusion 发展。
1. diffusion 模型
diffusion 模型是一种图像生成模型。在它之前,比较出名的图像生成模型是各种 GAN 模型,比如 StyleGAN、GauGAN 等等。
diffusion 模型做的事情很简单:去噪。具体而言,你给它一张有噪声的图片,它会尝试把这些噪声去掉一点点。
注意不是一下子全部去掉哦!因为一下子全部去掉的难度太大了,所以每次只去掉一点点就 OK。
这样的话,如果我们想生成全新的图片,该怎么做呢?也很简单,给它一张全是噪声的、随机生成出来的“图片”就可以了!因为它总是会一点一点地尝试去掉噪声,只要它去噪声的“次数”足够多,那么最终就能得到一张没有噪声的图片。
2. LDM 模型
diffusion 模型很不错,在 Stable Diffusion 之前也出了不少其它 diffusion 模型,也有开源的,甚至效果也都很好(比如 Disco Diffusion)。但为什么 Stable Diffusion 这么火呢?这就要来看看原始 diffusion 模型的缺点了。
让我们来看这么一个例子:假如我要生成一张 512*512 的图片,我该怎么做?按照之前的解释,我们就需要生成一个 512*512 的、全是噪声的“图片”,然后尝试让 diffusion 模型“去噪”——但这对硬件的负担太重了!因为 512*512 太大了,导致需要很强的硬件才能跑起来。而且即使跑起来了,跑的速度也会比较慢。
拿 Disco Diffusion 举例,可能就要几分钟甚至十几分钟,才能把最终的图片生成出来。
那我们自然会想:能不能把这个尺寸缩小一些,再喂给模型呢?答案是可以!Latent Diffusion Model(LDM)做的正是这么一件事。
简单来说,LDM 会先把图片“压缩”一下,然后再去处理 / 生成它。比如说,假如要生成一张 512*512 的图片,它会先按照 8 倍的倍率,先从 64*64 的、全是噪声的“图片”开始,生成一张 64*64 的、只有它自己能理解的“图片”。最后,再根据它自己的“压缩”规则,把这张 64*64 的“图片”“解压”成 512*512 的图片。
这么一来,由于压缩、解压过程都是比较简单的,而真正复杂的计算过程(或者说去噪过程)都是在压缩后的图片上进行的,所以对硬件的负担就大大降低,运行速度也大大加快了~
3. LDM 模型的应用
LDM 只是模型技术,如果要真正应用它的话,还需要告诉它具体做什么任务、并给它相应任务的数据来让它学习。在其中,笔者个人觉得比较好用的有三个:图像修补,风景合成,以及最近大火的——文本生成图像,也就是 Stable Diffusion。
在具体解释细节前,我们可以先从宏观上来看看,LDM 是怎么“学会”做一项任务的。大体上来说,我们需要告诉 LDM 两个关键事项:
1. 当前任务的“条件”是什么?
2. 当前任务希望根据给定的“条件”,生成怎样的图片?
然后再给它很多很多相关的数据就行。因此,图像修补、风景合成以及文本生成图像,本质的区别仅仅是“条件”的不同而已。
3.1. 图像修补(Inpainting)
图像修补做的是这么一件事:给定一张图像,如果我对某个区域不满意(比如,背景里有个路人,或者生成的人物多出来了一只手),那么可以通过图像修补的技术,把这个区域中的东西“修补掉”(比如,把路人去掉并补上合适的背景,或者把手去掉并补上合适的周边)。因此,对于图像修补而言,我们的“条件”有两个:
1. 待修补的图像
2. 想要修补的区域
把这俩条件扔给 LDM,在一顿操作后,它就能根据历史经验,尝试帮你把给它的区域给“修补掉”了~
3.2 风景合成
对于风景合成而言,“条件”是比较直观的:我们需要告诉 LDM,在一张图里面,哪些地方是山、哪些地方是河流、哪些地方是天空等等,然后 LDM 就会根据这些“条件”,去合成一张风景画来。
3.3 文本生成图像
这个的“条件”就更直观了:就是用户输入的文本!然后 LDM 就会去尝试根据文本,来生成一张图像。
4. LDM 的二三事
这时你可能就想问了:为什么 LDM 啥都能做?决定它能做这些任务的本质原因是什么?我能用同一个 LDM 模型做到所有这些任务吗?
4.1 为什么 LDM 啥都能做?
其实,并不是说只有 LDM 能做到这些,理论上所有 diffusion 模型都能做到这些。但是,由于前文提到的,LDM 跑起来更快、对硬件要求更低,所以学者会有功夫去让 LDM 把这些任务都做了。换句话说,能力大家都有,只是 LDM 做起来更快,所以可能出效果的速度也就更快。
当然了,我相信也已经有其它 diffusion 模型也做了这些任务,但笔者对 LDM 了解会更多一些,所以就不去妄议其它 diffusion 模型了~
4.2 决定它能做这些任务的本质原因是什么?
如果要说技术细节的话,那就是 LDM 的研究者们在开发 LDM 时,就充分考虑到了如何让模型能支持各种千奇百怪的“条件”。因此,他们采取的、识别“条件”的方法是很通用、很万能的,因此它能做包括这些任务在内的很多很多任务。
4.3 我能用同一个 LDM 模型做到所有这些任务吗?
很遗憾,至少目前来说,还不可以!因为除了让模型“有能力做到”之外,我们还需要保证它“有足够的学习材料”。就目前来说,这些任务中的每一个,对 LDM 来说已经很有挑战性了,所以就已经要给它足够的学习材料、或者说数据。如果很多个任务一起来的话,所需要的数据不是简单地相加,而是会组合式地增长(类似于相乘),同时也会让模型很为难:你怎么一下子让我做这个,一下子让我做那个?这样下来,有可能最后它会好像就什么都会一点点,但又好像什么都不会。
总之,还是让每个 LDM 都专注于一个任务比较好!
超分辨率相关
超分辨率,也就是能让图片变高清的一种技术。该技术自然也是可以通过 LDM 来实现的,此时的“条件”就是原图,然后我们希望模型能帮我们把它变高清。
但是这么做的话,会有点“大材小用”的感觉了:因为超分辨率相对来说是比较“简单”的任务!毕竟我们已经有了图片的全部信息了,所要做的只是增加一些细节而已。此时用 LDM,不免有“大炮打蚊子”之嫌。
(注:这里说“简单”,并不是说这项技术简单,而是指从信息转换的变化幅度来看,确实没那么大。比如文本生成图片,是直接把文本信息转成了图像信息,是两种完全不同的信息之间的转换,变化特别大;而超分辨率,只是把一张有完整信息的、相对糊一点的图,变成了高清一点的图,信息的变化就相对小一些。
因此,笔者最终采用的超分辨率模型,其实是一种针对超分辨率开发的模型,也是目前开源社区中最受欢迎的解决方案之一——Real-ESRGAN(https://github.com/xinntao/Real-ESRGAN)
(我感觉这个不是特别重点,可能可以简单略过?因为剩下的也就是些模型细节了哈哈哈
ai绘画原理
正如之前提到过的,当前的 AI 绘画基本都是基于 Diffusion 模型做的,而其中又以 Stable Diffusion 最为火爆。
按照之前的说法,AI 绘画无非是以文本作为“条件”的 LDM 模型,它的目标是生成与该文本描述相符合的图片。那么具体而言,它到底是怎么做的呢?
(以下就照搬我发给子言老师的微信了哈哈哈
直观来说,AI 为了学会作画,它会先去尝试理解,为什么某段文字会和某张图片是相似的。在看了足够多的例子之后,它就隐隐约约能捕捉到文字和图片的联系了,此时只要给它一段新的文字,它就会根据它的理解,去一点一点地把相似的图片给“画”出来。这里所谓的“一点一点”,正是它“一步一步”的去噪过程:
1. 一开始,它会知道最终的图片需要和什么文字相似,然后会面临一张全是噪声的“图片”
2. 此后的每一步,它都会把当前“图片”中的噪声给去掉一点点,以使去掉噪声后的“图片”尽可能与所给的文字相似
3. 等漫长的去噪过程结束后,就能得到一张符合文字描述的图片了
当然有个比较流行的梗就是,因为你给 AI 资料,它真的会去学怎么画,而且是没日没夜地去学!!!
无限画板原理
如果用过笔者 Nolibox Creator,就会发现这个产品是一个“无限画板”——你可以放大、缩小、拖拽——而且似乎没有边界!
那么,为什么能够做到放大、缩小、拖拽呢?它真的是“无限”的吗?背后的数据是怎么存储的?
1. 背后的数据是怎么存储的?
往简单来说的话,其实无限画板并不复杂。可以这么理解:画板上的每一张图都是一个“节点”,我们会去记录这些“节点”的位置信息,同时会记录一下当前屏幕上的“画板区域”,从而:
1. 当一个“节点”位于这个区域内,就把它“画出来”
2. 否则,就不去管它,也不浪费精力去画它
这样一来,即使这个无限画板上有成千上万张图(或者说,成千上万个节点),当前屏幕上所对应的区域内的节点也可能不会特别多(比如十几个或者几十个),从而电脑能够承受得住
(所以,如果屏幕上确实同时出现了很多图……不说成千上万,就说 100 张,可能就已经会开始体验到卡卡的感觉了~
2. 它真的是“无限”的吗?
严格来说,并不是:因为计算机本身能处理的数字是有限的,所以这块画板当然也会受到相应的限制。但一般来说,我们触碰不到这个界限,所以认为是“无限”的也无不可~
3. 为什么能够做到放大、缩小、拖拽呢?
前面我提到,我们会记录一下当前屏幕上的“画板区域”。用另一种角度去看,我们可以把我们的屏幕,理解为“摄像头”:它无时无刻不在拍摄着我们的画板,然后把影像传递给我们的屏幕。
这样的话,放大、缩小、拖拽就都好理解了:
1. “放大”就是把“摄像头”的缩放倍率调大
2. “缩小”就是把“摄像头”的缩放倍率调小
3. “拖拽”就是移动“摄像头”本身
然后我们只需要记录一下这个“摄像头”的缩放倍率和移动距离,就能复原出放大、缩小、拖拽的效果了~
文章来源于网络,如有侵权,请联系我们小二删除,どうもで~す!
回复
使用道具
举报
返回列表
发新帖
游客
回复
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
发表回复
快速回复
返回顶部
返回列表
 官方Q群
官方Q群




 发表于 2023-4-6 15:05:51
发表于 2023-4-6 15:05:51